REST API Code Sprint Results
After an epic week of work on the REST-API as a team we are happy to report back with both a pull request and this status update on the work performed.
Thanks again to the code sprint sponsors, we really appreciated the strong response - it was great going into the event knowing it was not going to lose money. We would also like to thank our in-kind sponsors including our hosts GeoSolutions.

![]()
![]()
![]()
![]()

![]()
![]()
![]()
Previously posts in this series are REST API Code Sprint Prep and GeoServer Code Sprint 2017.
Migration to Spring-MVC
Everyone worked hard:
-
310 commits
-
487 files changed
-
33,896 lines of code modified
-
More than 500 person-hours over the course of one week.
We have a post on rest api code sprint prep - here is what that work looks like visually.
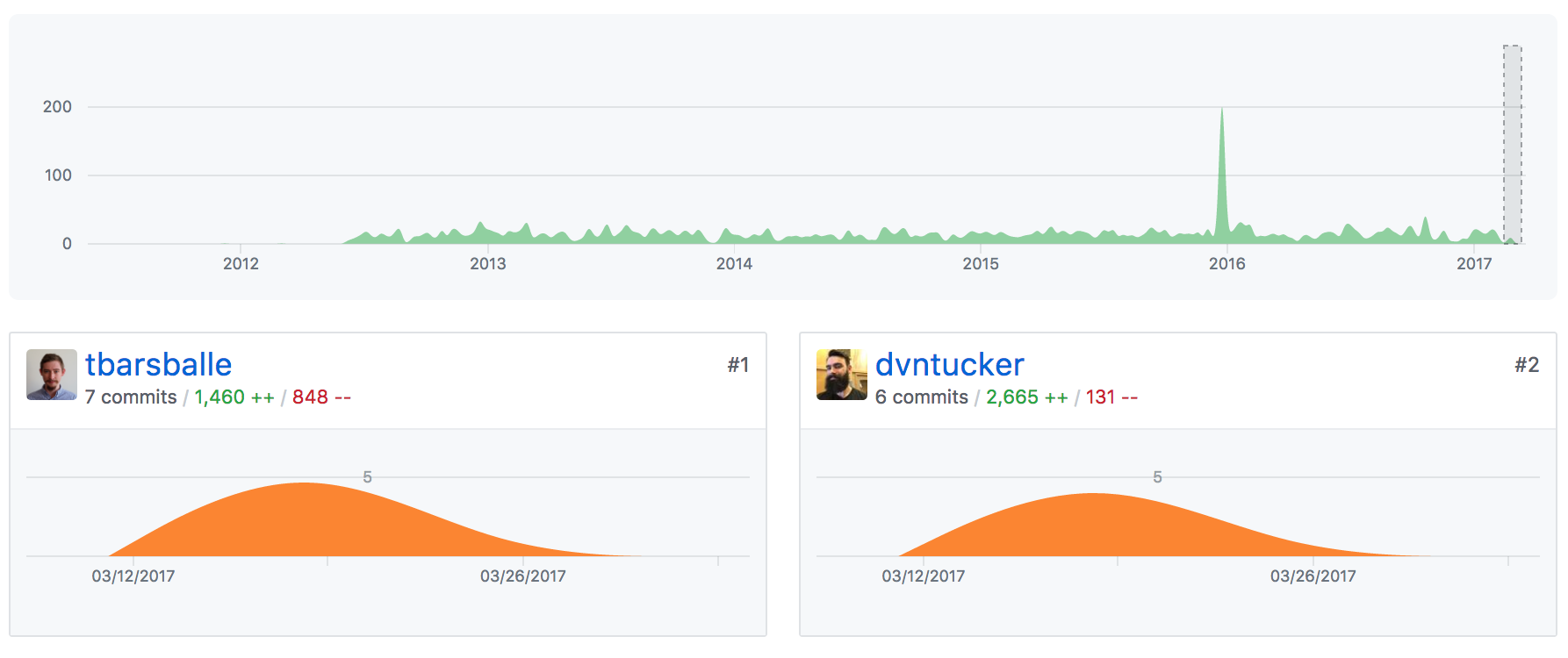
When reading the above graphics pay attention to the number of lines changed, rather than the number of commits, since some developers commit more frequently than others. A big thanks to Devon Tucker for doing the initial legwork, porting over the /rest/styles end-point sorting out the initial base-controllers, converters and configuration for the spring-mvc approach. Torben Barsballe joined to tinker on html output, javadocs and path fixes so everyone could have a consistent example.
During the sprint itself we carried on this work, splitting up according to end-point. Here is what that looks like visually.
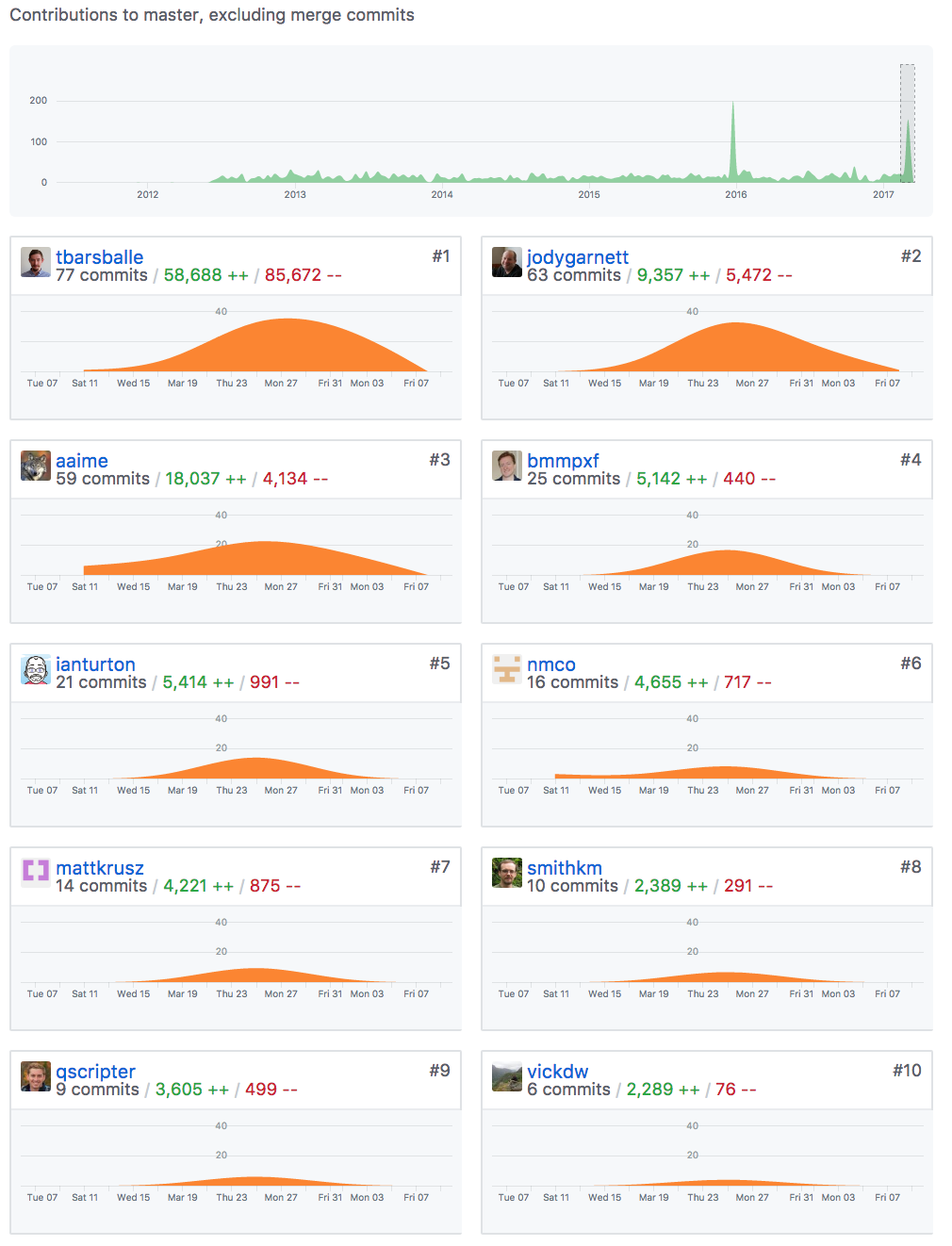
The base /rest end-point provides an HTML and JSON list of all the other endpoints. Torben was able to implement using by looking up path mapping at runtime, allowing us to list new rest-api end-points that are added by optional modules such as the backup-restore community module.
The/rest/workspaces and/rest/namespaces were ported by Ian Turton who joined us from the United Kingdom. These two end-points work in tandem, and are responsible for partitioning GeoServer’s configuration for ease of management, with each workspace being assigned an XML namespace (so their output will not conflict).
Next we have David Vick working on the /rest/{workspace}/datastores end-point. This end-point is responsible for managing vector data sources, this was especially challenging to document since the connection parameters are different for each kind of connection.
Andrea Aime drove down to the coast from to joint the sprint. Initially working on the the /rest/{workspace}/coveragestores end-points, responsible for managing raster data sources, including file upload. Andrea was the first to finish migration and move on to documentation with Mike Pumphrey. This was an especially comlicated end-point as it also covers index and granules management for structured coverages (such as image mosaic).
From Canada Jody Garnett helped with documentation builds, and porting the /rest/layers end-points. The layers end-point captures the WFS options and WMS styling required when publishing.
Nuno, joining us Portugal, worked on the /rest/{workspace}/coverages end-points. Each coverage represents a resource published as a layer. This makes it a tricky to work as both the coverages and layers end-point needs to be used together to effect change.
Matt Kruszewski, joining from St. Louis, provided technical experience to guide the documentation effort. For migration Matt worked on the /rest/{workspace}/featuretypes end-point. Each featuretype represents vector data that is published as a layer, once again requiring use of both the featuretypes and layers end-points together.
Kevin Smith, over from Canada, worked on the /rest/{workspaces}/wmsstores and /rest/{workspaces}/wmslayers end-points. These endpoints are responsible for managing cascaded WMS services, and shared many of the same challenges as the datastores and coverages endpoints.
Quinn Scriptor flew in from Washington District of Columbia, helping with the documentation publication and porting the /rest/layergroups end-points. This work was made more challenging due to an inital lack of test coverage, requiring Quinn to write tests prior to migration.
Several developers were able to go back for a second helping, porting the remaining end-points:
-
/rest/fonts was ported by Ian
-
/rest/about was ported by Matt
-
/rest (index) was ported by Torben
-
/rest/settings were ported by Quinn and Torben. Quinn had to dig into the settings for each of the OWS Services.
-
/rest/templates were ported by Jody
-
/rest/security was ported, at some cost to personal sanity, by Andrea.
-
**/rest/resources **was ported by Torben. This proved tricky as the end-point is willing to work with a wide range of mimetypes (as it is used to manage configuration files, icons and fonts).
After the core application was migrated we had a chance to work on the extensions.
-
The /rest/imports extension was a team effort with Ian David, Matt and Torben on task. Torben especially worked on the airplane ride home and far into the next week migrating the tasks section of this api (responsible for monitoring long running import activities).
-
The /rest/monitor extension was the work of Andrea. This proved difficult to migrate unchanged, as the original notification model was tied into the restlet life-cycle. This work was extensive requiring re-implementing all the dispatcher callbacks in core.
-
Finally Nuno migrated the /rest/services/wfs/transforms end-point used to define XSLT transformations on WFS output.

Documentation
One thing everyone we talked to was looking forward to was reference documentation for the rest api. We have mixed success to report.
We were unable to “auto generate” swagger documentation starting from our existing java codebase. The XStream library we use for XML/JSON output cannot be automatically scanned to produce a swagger file.
What we were able to do was form a documentation train, as each developer completed the migration of a rest-api endpoint they would visit Mike Pumphrey and get started on producing a swagger document by hand. These text files explicitly document each end point, the path, the queries, and most importantly the data that can be edited.
Once the swagger document had been produced we then had a chance to look into publishing options.
From each rest api in the user documentation we link to the generated reference docs.
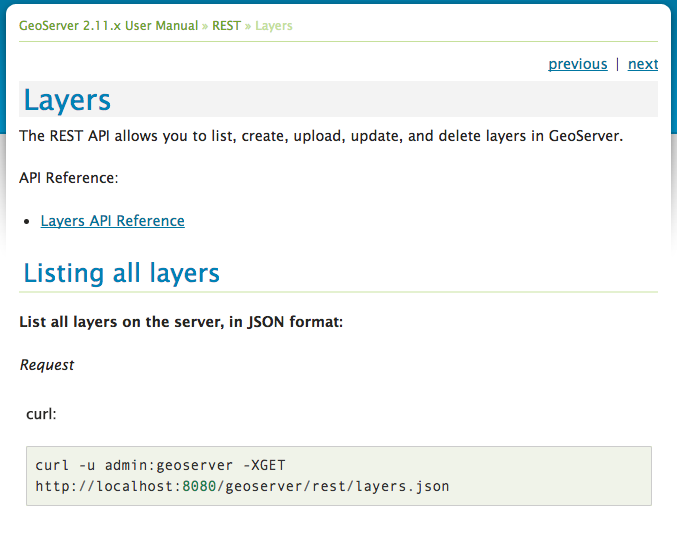
Static documentation for the user guide
Generation of static html files for the user guide was straight forward using the swagger-codegen-maven-plugin, but only used about 70% of the information we had so carefully written!
Our first issue with this approach is the generated documentation has a bad habit of sorting alphabetically each end point. So all the DELETE methods would be grouped, followed by GET, and then POST, and then PUT methods.
To address this we have broken up each end-point into a seperate file (rather than have a single reference for everything).
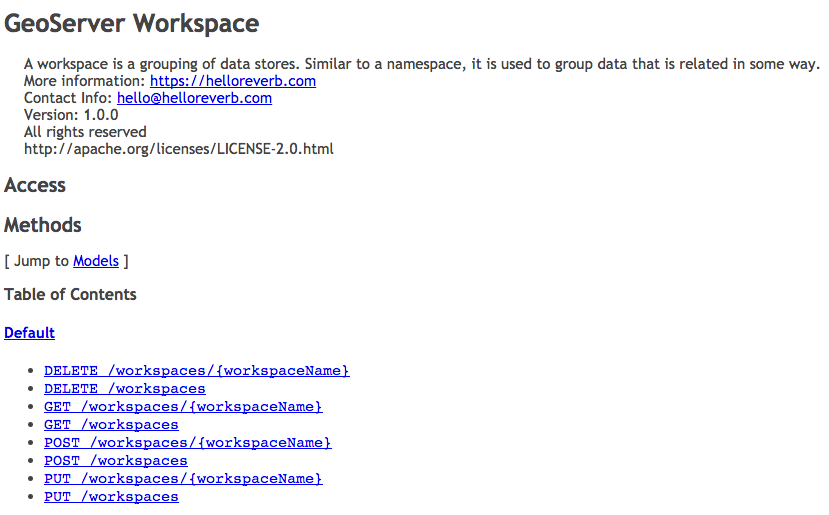
Looking at an individual reference we can start to see everything we have written, but the XML and JSON examples have been reduced to a single line.
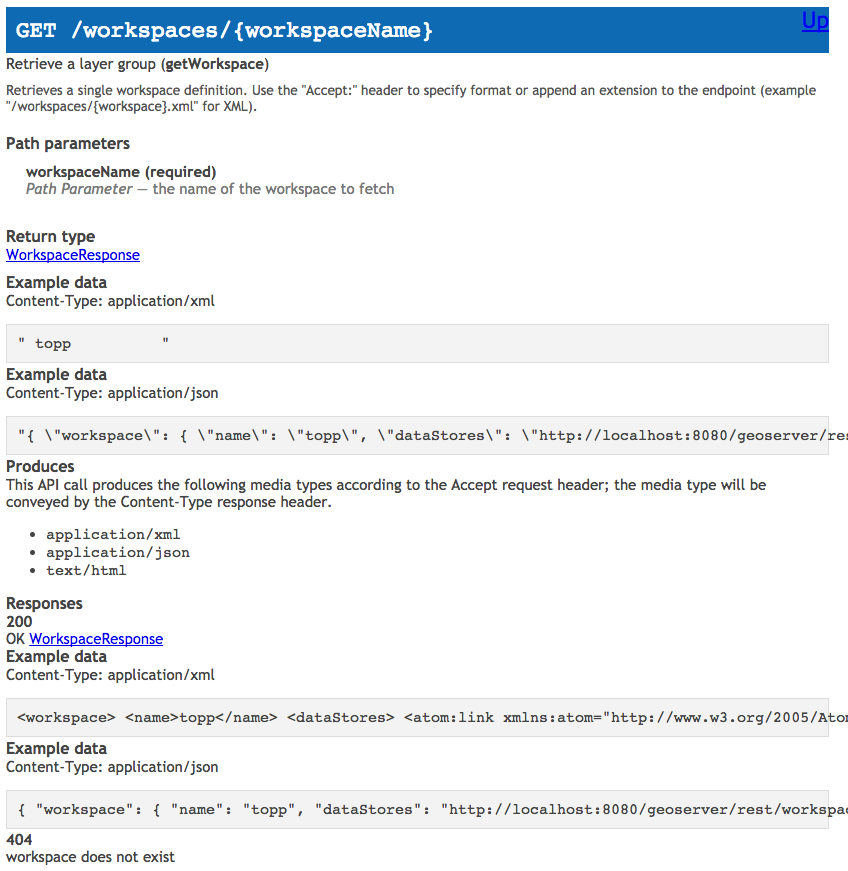
These results were disappointing after so much work. I expect we will need to improve this plugin if we continue to use it as is.
Generating dynamic documentation for the website
The swagger documentation that most people are familiar with is JavaScript based, showing a YAML or JSON api definition as an interactive dynamic reference. What is great about this approach is that the JavaScript documentation viewer can construct valid sample requests and run them against a reference GeoServer.
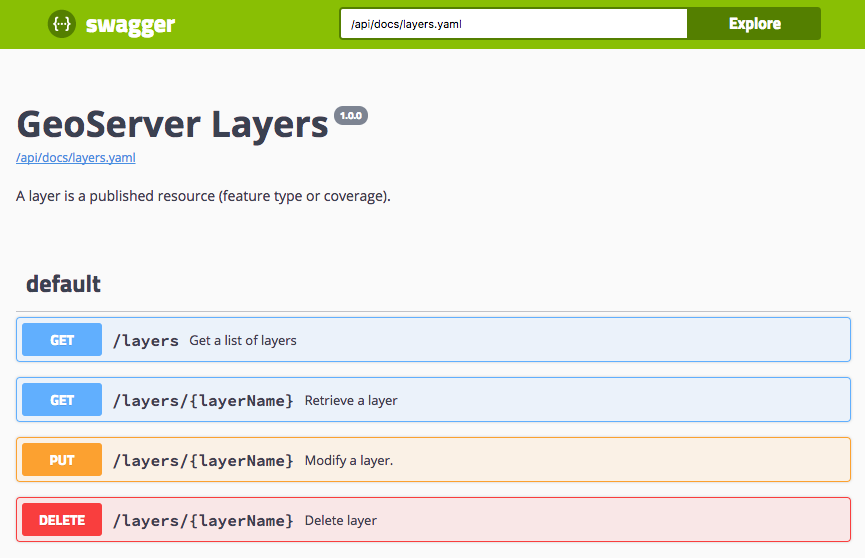
Opening up one of the operations we can see that it is much more readable.
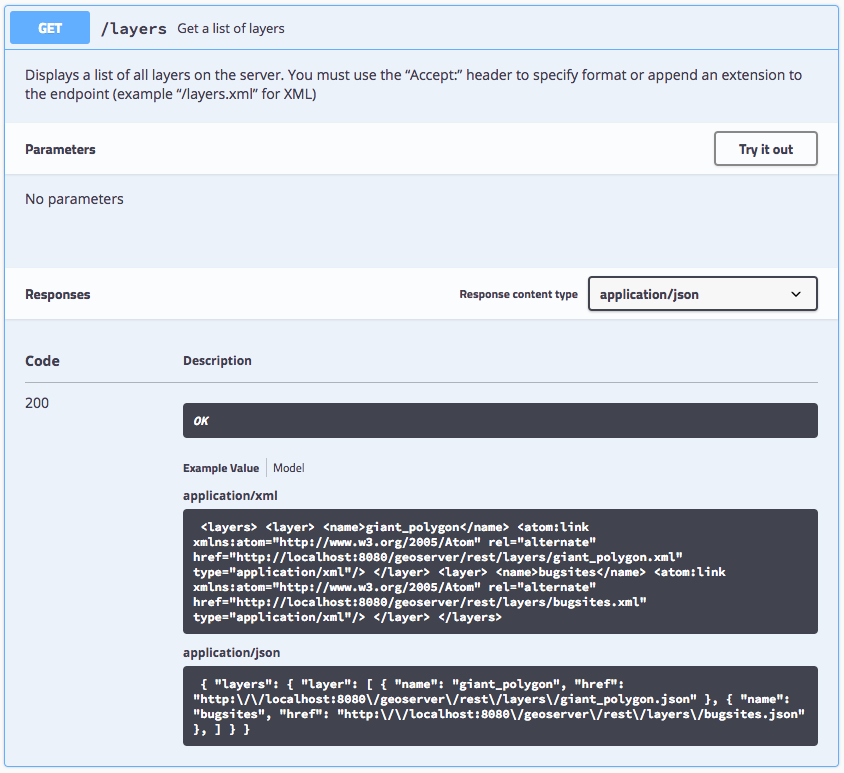
For a GET method the response code are clearly listed, with an opportunity to provide an example value. There are still some glitches (the XML and JSON are not pretty printed).
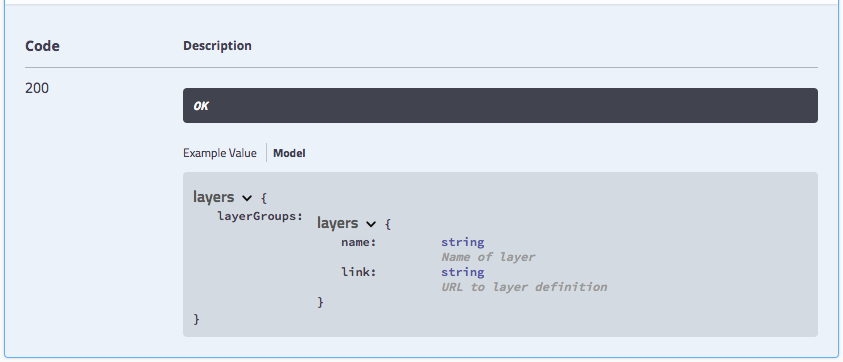
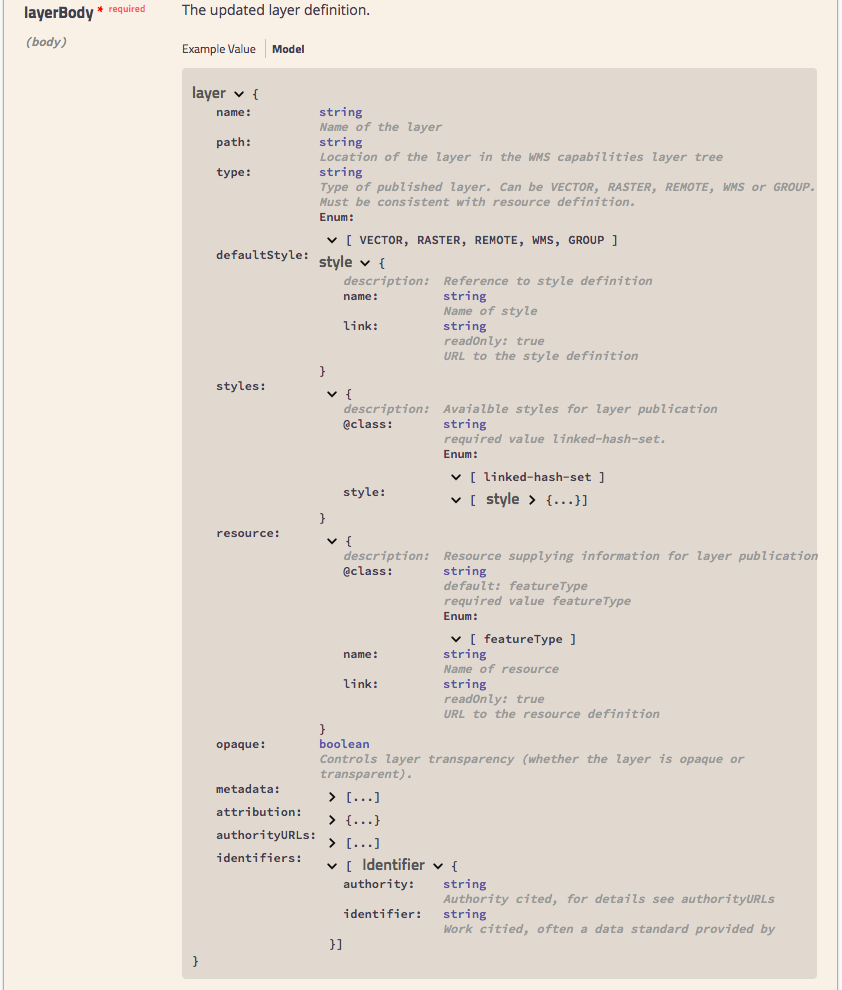
Changing from example value to model we can start to reference information that has been written during the sprint. Since this model is common to both XML and JSON we have tried to strike a good compromise using link to document an atom:link in XML, and a href in JSON.
For PUT and POST methods attribute values (including path variables) are documented, along with the request body.
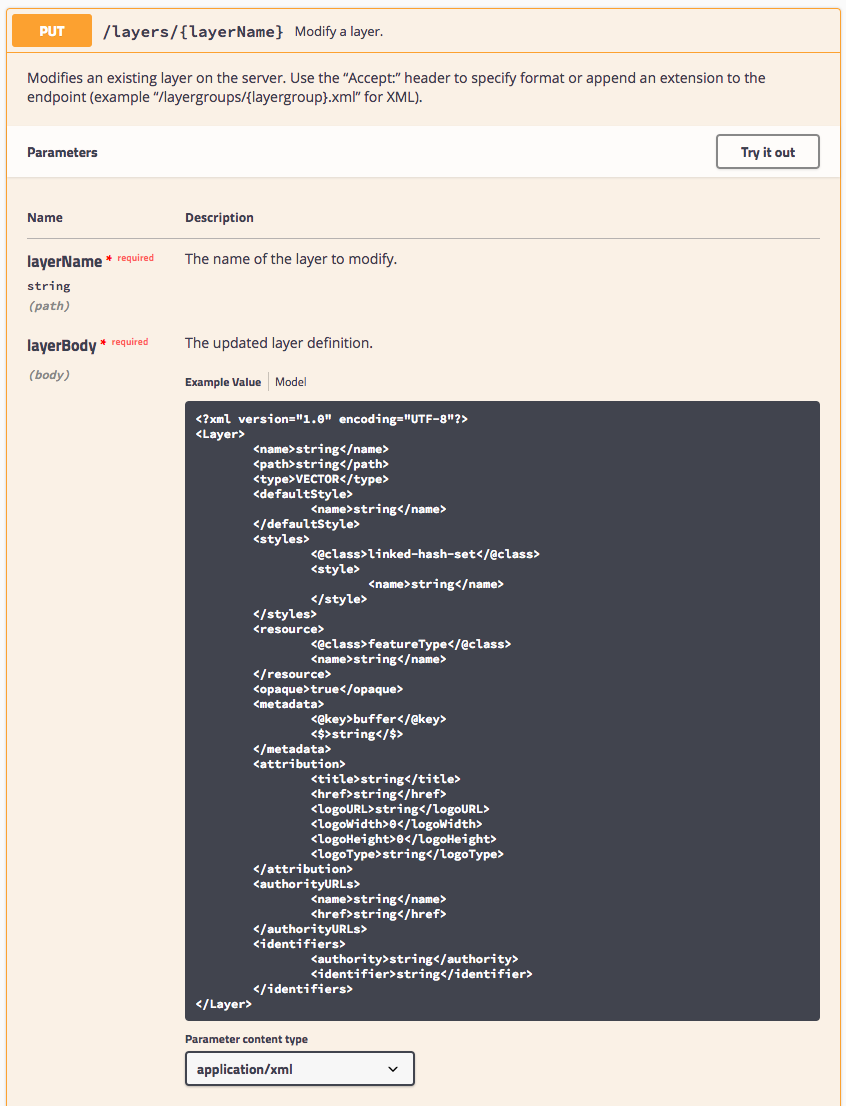
The model for the request body, drills down into the content expected. One nice feature is the ability to reuse definitions - as seen in the result of style for default and alternate elements below.
To share this with you today we have added docs.geoserver.org/api to the website, the documentation viewer is able to access the individual YAML files on that website.
For the GeoServer 2.12 release we would like to try repurposing this viewer for static html use, it will involve generating out a web page that includes each YAML file inline in addition to the documentation viewer.

Delivery
While the above work was accomplished during the sprint at GeoSolutions, the work was not in a fit state for a delivery. Over the next week (and weekend for Andrea):
-
Integration testing (for geoserver-manager java library and part of gsconfig) from Andrea found a large number of issues. The bulk of these were regressions caused by not quite following the previous example. While this would not normally be a problem when creating a new API, we wanted to be sure to produce the same workflow and response codes so that downstream applications would continue to work unchanged.
-
Kevin Smith and Jody worked to double check the css and ysld extensions correctly worked with the migrated styles end-point. This resulted in some small improvements - css and ysld content can now be validated on upload.
-
Integration testing (for gsconfig and gsimporter python libraries) took up much of the next week as Torben first implemented the remaining “import tasks” and continued quality assurance work Andrea started.
-
Jody and Torben had the final consistency run, making sure converters were were being used consistently to handle mime types, and checking that path variables were named consistently across all endpoint controllers.
-
Torben had the honor of producing the final pull request on Friday (a full week after the sprint completed). These final checks for headers, code formatting, consistent use of path annotations provide us a firm codebase to work from in the future.

Thanks
We would like to thank our employers for a chance to work on this activity, the sponsors who made it possible to work together in person, and our hosts at GeoSolutions for their hospitality.

